
2024 年 12 月 26 日,DeepSeek 正式发布 DeepSeek-V3 模型,性能对齐海外领军闭 源模型。2025 年 1 月 20 日,DeepSeek 发布 DeepSeek-R1 模型,并同步开源模型 权重,性能对齐 OpenAI-o1 正式版。
DeepSeek 有望加速高阶智能驾驶落地
DeepSeek 对底层架构、训练框架、模型推理等方面进行了关键创新,实现了与全球领军 A I 模型的匹敌,对智能驾驶的开发有重要借鉴意义。数据生成方面,可通过数据增强和合成来应对极端场景。数据处理方面,借鉴 DeepSeek 流式数据处理方式,结合边缘计算、记忆回放等技术实时数据处理与增量学习。同时借鉴知识蒸 馏降低数据依赖提升智能驾驶开发效率,并结合跨模态对齐将智能驾驶模型能力 在车端轻量化部署,以适应不同配置的车型,有望加速高阶智驾落地。
DeepSeek 是智驾重要工具,而非颠覆格局
DeepSeek 作为开源基础模型,引入后有望加速智能驾驶的训练速度,降低智能驾驶的训练成本,未来有望成为智驾训练的主要工具,同时,优质云端模型和强蒸馏 能力成为影响迭代效率的关键因素。DeepSeek 或无法改变行业格局,一方面智能 驾驶安全边界较高,仍需要较长训练时长保证功能安全;另一方面针对不同车型 算力和架构,蒸馏后仍需要完成定向开发。未来功能实现层面来看,尚未实现智能 驾驶功能完整性部署前,DeepSeek 的使用或加速缩小各家车企之间的时间差距。实现功能突破后,智能驾驶领先企业有望保持用户粘性和高阶功能性能的领先。
DeepSeek 的底层架构和技术创新对智能驾驶开发具有重要的借鉴意义,有望加速高阶智驾落地,产业链有望迎来新的投资机遇。整车推荐理想汽车、小鹏汽车、比亚迪、吉利汽车、赛力斯、长安汽车、上汽集团等。零部件厂商推荐电连技术、伯 特利、经纬恒润、德赛西威等。
1. DeepSeek 有望加速高阶智能驾驶落地
1.1 DeepSeek 引领 A I 产业技术革新
DeepSeek 技术创新引领 A I 产业变革。随着 2024 年底以及 2025 年初深度求索发布 DeepSeek-V3 和 DeepSeek-R1 模型,凭借一系列独创性和改进性技术以及精妙的策 略,实现了与全球最强 A I 模型的匹敌,标志着我国在 A I 大模型领域实现技术突破。训练端,DeepSeek 通过自研 DualPipe 训练框架、8 位浮点量化技术、改进的MoE 和 MTP 等创新技术,有效提升了计算效率,大幅降低训练成本。推理端,DeepSeek 通过 MLA 技术、改进的RL 和蒸馏技术,大幅提升了推理效率,其性能可与全球顶尖 A I 模型匹敌。我们认为,凭借架构和算法的优化以及全面开源策略,DeepSeek 有望引领全球 A I 大模型技术革新,加速 A I 大模型在各个领域的应用落地。
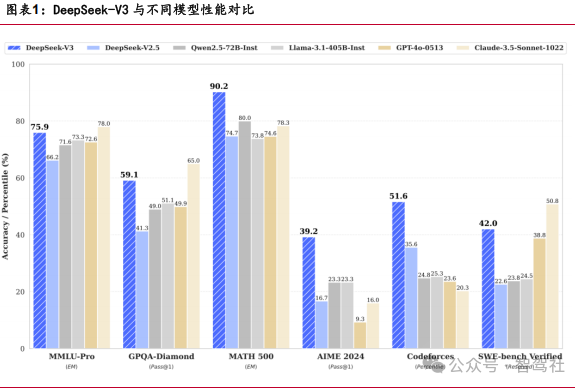
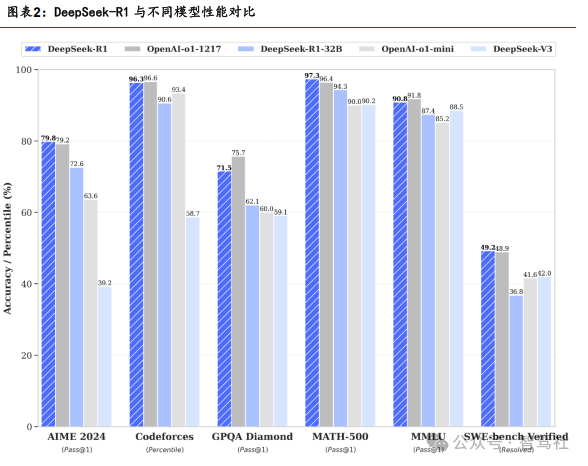
DeepSeek 通过技术创新实现高性能和低成本。架构方面, DeepSeek-V3 基于 Transformer 框架 , 通过多头潜在注意力(MLA)、 DeepSeek 混合专家模型 (DeepSeekMoE)、无辅助损失的负载均衡策略以及多令牌预测(MTP)等核心创新进 行架构设计。训练方面,通过自研 DualPipe 算法和基于FP8 数据格式的混合精度训练框架,减少训练内存需求,提升训练效率。推理方面,DeepSeek-R1 基于 DeepSeek- V3 基础模型,通过大规模强化学习技术增强推理能力,成功地将强化学习带来的强 推理能力泛化到其他领域;同时采用模型蒸馏技术,显著提升小模型的推理能力。
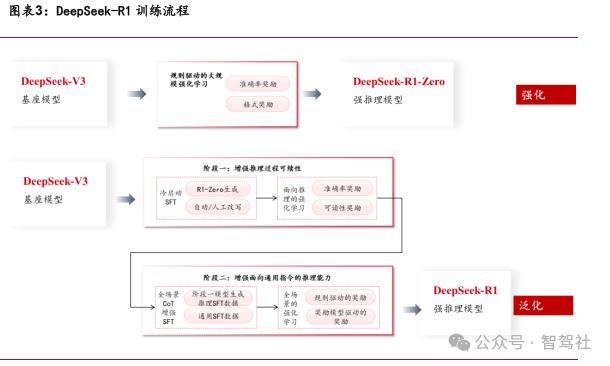
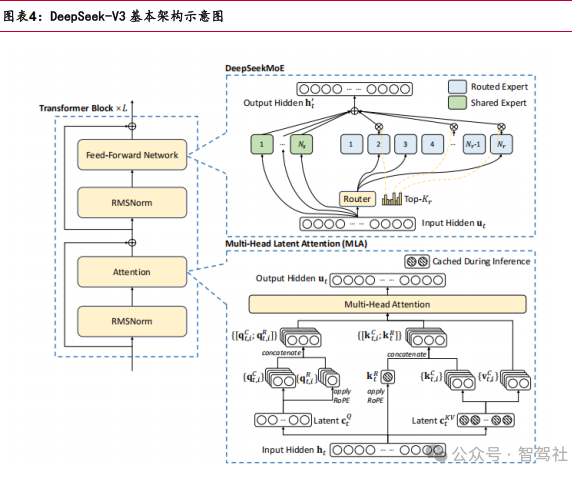
DeepSeek-V3 架构创新
公司在模型架构设计上基于 Transformer框架进行创新。MLA(Multi-Latent Memory)多头潜在注意力机制通过压缩注意力机制减少所需要处理的信息量,提高效率; DeepSeekMoE 架构则采用更细粒度的专家和共享专家提升训练效率;无辅助损失的负载均衡则确保专家间工作量均衡,不依赖额外损失项;多令牌预测 MTP 则提高模型 的预测能力和数据效率。
(1) MLA(Multi-Latent Memory)多头潜在注意力:MLA 通过低秩联合压缩 注意力的键和值,减少推理时的 Key-Value(KV)缓存,提升推理效率。
(2) DeepSeekMoE:传统 MoE 依赖辅助损失平衡专家负载,但可能损害模型性 能。DeepSeek-V3 提出动态偏置调整策略,通过监控专家负载并实时调 整路由偏置,实现均衡分配,同时避免性能损失。DeepSeekMoE 使用细 粒度专家并设置共享专家,每个 MoE 层配置了 1 个共享专家和 256 个路 由专家,每个输入token 可以激活 8 个路由专家,在保证模型处理效果 的同时避免过度激活专家带来的计算资源浪费。同时支持跨节点通信优 化,结合无辅助损失的负载均衡策略,确保训练时专家负载平衡,提高计算效率。
(3)多令牌预测(Multi-Token Prediction, MTP):通过设置多词元预测训练目标,让模型预测多个未来词元,增强训练信号,提升模型性能,还 可用于推测解码加速推理。
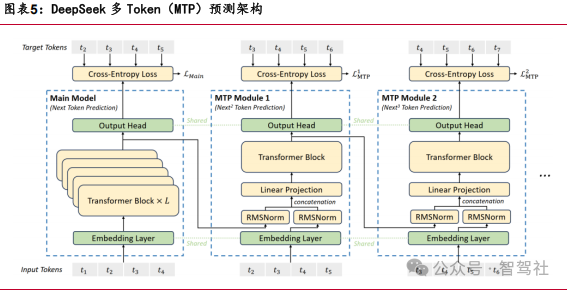
DeepSeek 训练方式的创新
DeepSeek-V3 和 DeepSeek-R1 均基于大规模预训练,使用了创新性的训练算法和框架 实现低成本高性能,如 FP8 混合精度训练框架、DualPipe 算法。DeepSeek 通过运用 FP8 混合精度训练框架,采用分块量化和动态缩放策略,结合 DualPipe 算法、节点限制路由及无令牌丢弃等技术,在超大规模模型训练中实现了训练效率提升、内存占用减少与训练稳定性的平衡。DeepSeek 对核心计算采用 FP8 精度以加速训练、减少内存消耗,同时对部分关键组件保持较高精度以保证稳定性。首次在超大规模模型上 验证 FP8 训练的可行性,通过分块量化(Tile-wise)和动态缩放策略解决低精度溢 出问题,在保持训练稳定性的同时提升计算速度并减少 GPU内存占用。通过 DualPipe 算法实现高效的流水线并行,重叠计算和通信阶段,减少流水线气泡;采用节点限制 路由、无令牌丢弃等技术优化训练过程。
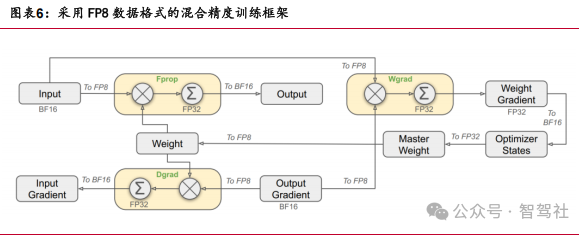
强化学习在大语言模型中的应用
DeepSeek-R1-Zero 采用组相对策略优化(GRPO)算法进行强化学习。DeepSeek-R1- Zero 以 DeepSeek-V3 为基础模型,直接应用强化学习(RL),通过 Group Relative Policy Optimization(GRPO)算法优化模型策略,采用基于规则的奖励模型引导训 练。DeepSeek-R1-Zero 直接基于基础模型(如 DeepSeek-V3-Base)通过大规模强化 学习(RL)训练,无需任何监督微调(SFT)数据,仅依赖规则化奖励(如答案正确性、格式规范性)驱动模型自我进化。采用 GRPO(Group Relative Policy Optimization)算法,通过组内样本的奖励相对比优化策略模型,降低计算成本。
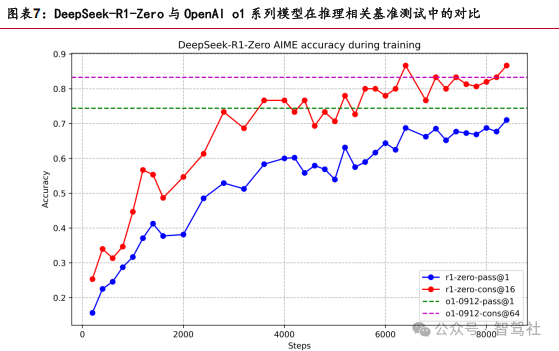
DeepSeek-R1 采用多阶段训练进一步提升推理能力。DeepSeek-R1 引入冷启动数据进 行多阶段训练,结合推理导向的 RL、拒绝采样和监督微调等方法提升推理性能。DeepSeek-R1 在 R1-Zero 的基础上引入冷启动数据(少量高质量人工标注的长链推理 示例)进行初步 SFT,随后分阶段结合强化学习 RL 训练:
(1)首先推理导向的强化学习RL,针对数学、代码等结构化任务优化;
(2)其次,通用场景强化学习 RL,融合人类偏好(如可读性、无害性),平衡推理性能与用户体验;
(3)最后,拒绝采样与再训练 RL,通过模型生成数据筛选高质量样本,结合非推理任务数据(如写作、翻译等)进行二次 SFT。
模型蒸馏显著提升小模型推理能力
DeepSeek-R1 的推理能力被蒸馏到 DeepSeek-V3 中,生成高质量的训练样本并进行监 督微调。知识蒸馏(Knowledge Distillation)是一种模型压缩技术,用于将大型复 杂模型(教师模型)的知识迁移到小型模型(学生模型)中,以提高学生模型的性能, 同时保持模型的高效性和可扩展性。具体来说,DeepSeek-R1 生成高质量的训练样本, 这些样本被用作 DeepSeek-V3 的训练数据,从而显著提升了 DeepSeek-V3 的推理能 力。
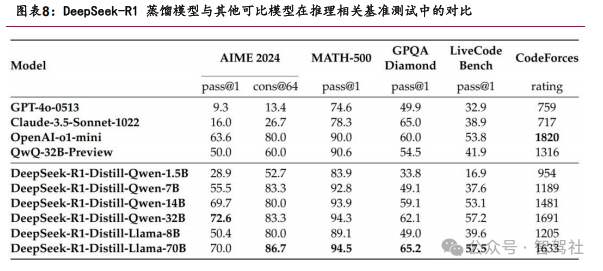
1.2 DeepSeek 技术创新对智能驾驶有重要借鉴意义
DeepSeek 有望加速高阶智驾落地。DeepSeek 在 A I 领域的优势主要源于它具备高效架构设计、先进算法、数据处理与增强、优化与加速、持续学习与更新、安全与隐私、用户体验优化。我们认为,DeepSeek 对高阶智能驾驶的开发落地有重要的借鉴意义, 有望加速高阶智能驾驶应用落地。数据生成方面,可通过数据增强和合成来应对极端场景。数据处理方面,采用 DeepSeek 流式数据处理方式,结合边缘计算、弹性权重巩固等技术,实现自动驾驶中的实时数据处理与增量学习。模型处理方面,可通过小样本学习降低数据依赖,同时通过跨模态对齐和知识蒸馏,将智能驾驶模型能力在车端轻量化部署,以适应不同配置的车型,加速高阶智驾落地。
通过数据增强和合成应对智能驾驶极端场景。汽车行驶环境非常复杂,真实路测难以覆盖所有危险场景(如行人突然横穿马路)。DeepSeek 可构建高保真的虚拟驾驶场景(如极端天气、突发事故),通过合成数据训练智能驾驶模型,从而补充真实路测数据中极端场景数据的不足,提升模型对复杂场景的适应能力。DeepSeek 通过构建“语言模型引导-物理引擎渲染-闭环评估优化”的新型数据工厂,可有效提升极端场景覆盖度,使模型提前学习应对策略,避免实际路测中的安全隐患。通过云端协同的方式, 将数据合成和仿真训练在云端完成,车端仅需加载轻量化模型。
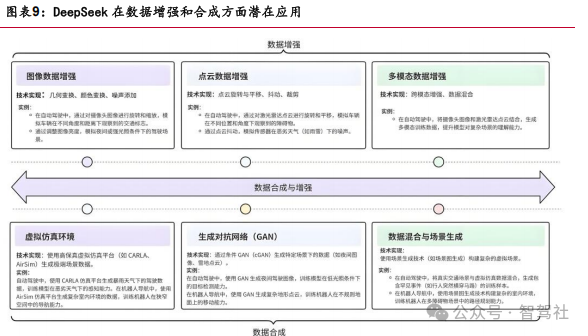
DeepSeek 思维方法助力智能驾驶数据实时处理。通过边缘计算在车端部署轻量化模 型,实时处理摄像头、激光雷达等传感器数据,实现低延迟决策。同时借助增量学习 在车端注入新数据持续优化模型。采用DeepSeek 流式数据处理方式,结合边缘计算、在线学习、记忆回放、弹性权重巩固等技术,实现自动驾驶中的实时数据处理与增量 学习。可提升系统的实时性和适应性,同时还可确保模型能够持续优化,适应动态环 境的需求。
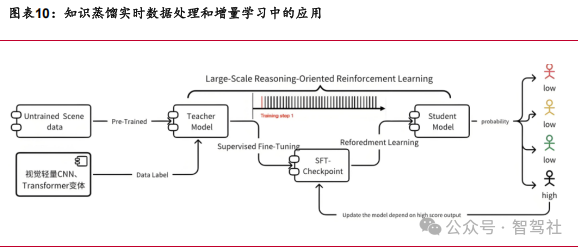
DeepSeek 小样本学习可降低数据依赖。参考 DeepSeek 知识蒸馏技术,通过少量真实 驾驶数据,如不同城市的交通规则,快速适配新环境。结合预训练模型迁移应用,先在大规模通用驾驶数据上进行预训练,再用少量本地数据微调,减少对大量特定场景数据的依赖,提高模型的适应性和泛化能力。知识蒸馏可应用于自动驾驶的感知、预测和决策模块。在感知模块,教师模型进行目标检测或语义分割,学生模型模仿其输出,减少计算量的同时保持检测精度;预测模块中,学生模型学习教师模型的轨迹预测结果;决策模块里,学生模型模仿教师模型生成驾驶策略。

知识蒸馏助力智能驾驶开发。DeepSeek 利用蒸馏技术将数据蒸馏和模型蒸馏相结合, 实现了从大型复杂模型到小型高效模型的知识迁移。知识蒸馏过程中,DeepSeek 设计了混合损失函数,类似于在具身智能领域所应用的预训练与微调技术。DeepSeek 具备的自我进化能力可自发产生高级推理行为,且能够对这些推理进行评估和进一步探索,可将这种性能利用到基于基础驾驶场景的泛化设计处理中。DeepSeek 中知识蒸馏技术中应用 SFT 监督微处理模式,DeepSeek-R1 则综合考虑在训练初期构建并收集少量高质量的长思维链数据(进行多步推理、长期记忆和上下文关联的数据), 引导模型生成详细结果,并以此对模型进行微调,这样便可作为初始的强化学习 RL 训练的起点。借鉴此模式,智能驾驶系统开发可以是已经完成监督学习后形成的高质量标注专家数据,类似 LSTM 网络结合 Transformer 的处理方式对每个图像 Token 进行处理。结合这种技术思路,业界正在探索绕过传统的监督微调步骤,直接在基础模型上开展强化学习,让模型在自我探索中挖掘推理潜力。也可以减少了对大规模标注数据的依赖,降低数据收集和标注成本,还赋予模型自主学习复杂推理策略的能力。通过模型不断的与环境进行交互,从环境反馈中学习最优行为策略,这样在感知获取信息时,模型就会根据感知到的具体环境内容结合人类赋予这一具身AI Agent 的任务项,自主判断该场景下需要调用的合适且符合安全的处理策略。
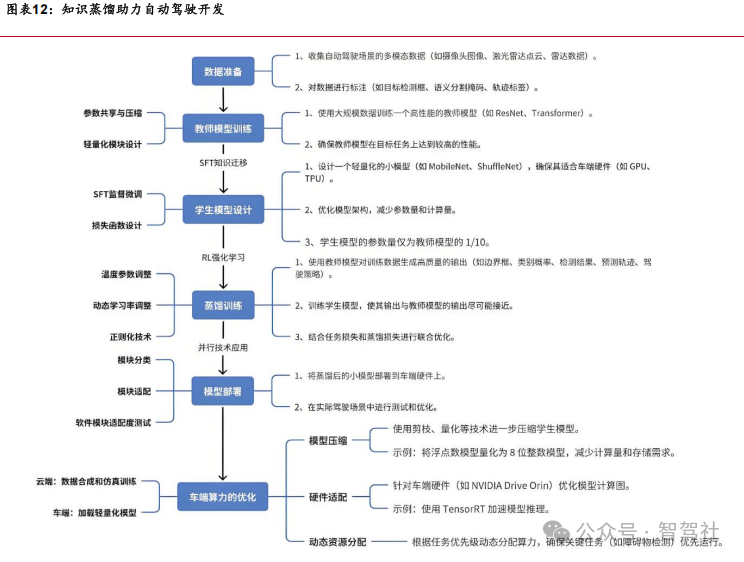
DeepSeek 技术可直接应用于智能座舱,但在智能驾驶开发应用仍有诸多挑战,如需模态对齐、时延、可靠性等方面均存在差异。DeepSeek 凭借架构创新、低成本高效 能、广泛的应用场景与开源社区支持等优势,可在汽车智能化领域广泛应用,如智能驾驶、智能座舱。
(1) 智能座舱:DeepSeek 作为大语言模型,可直接应用于智能座舱场景。
DeepSeek 模型在汽车智能座舱领域的应用场景正通过算法优化和低成 本部署展现出显著优势,其核心价值体现在提升交互体验、赋能功能创 新及优化本地化部署效率等方面。多家车企纷纷开启 DeepSeek 在智能 座舱的应用,吉利汽车正式宣布其自研的星睿大模型与 DeepSeek R1 大模型已完成深度融合;岚图汽车也已完成与 DeepSeek 模型的深度融合。 岚图知音或将成为汽车行业首个融合 DeepSeek 的量产车型,2 月 14 日 有望发布 OTA 来更新部分 A I 功能。
(2) DeepSeek 在智能驾驶场景面临诸多挑战, 主要是智能驾驶模型与
DeepSeek 存在模态差异,且智能驾驶模型对时延、可靠性等方面要求更 加严苛。模态方面,智能驾驶感知阶段的主要处理对象是像素点(包括 图像和点云);规划阶段的主要处理对象是离散的图论节点;控制阶段的主要处理对象是反映车辆运动状态的浮点数。而 DeepSeek 的主要处理 对象是作为语言原子单元的 token。因此,在利用 DeepSeek 模型时需要 进行多模态扩展,即提前进行任务对齐与模型改造。通过调整 DeepSeek- R1 的输出层或中间层,使其与学生模型任务对齐(例如,DeepSeek-R1 若以 NLP 任务为主,其知识迁移至自动驾驶 CV 任务需解决模态差异。需 要将语言生成任务输出转换为目标检测的边界框预测,过程中可能会用 到跨模态蒸馏技术对齐视觉-语言特征)。时延方面,车端模型对延迟要求较高(如 10ms 内完成一帧处理), 因此需要将蒸馏后的车端小模型所需的算力、存储等资源与车载芯片匹配。可靠性方面,智能驾驶场景下 要求模型决策高可靠,需在设计蒸馏损失函数时加入安全约束(如关键 场景的误差加权惩罚),并验证学生模型的可解释性。
2. DeepSeek 是智驾重要工具,而非颠覆格局
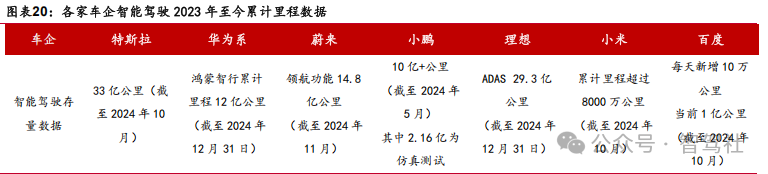
当前智能驾驶路线进展:L3 到L4升级对MP I要求更高,模型升级路径或放弃Learning by Watching 的模式。 目前处于 L3 到 L4 升级的关键节点。其中,MPI数据的优化 (Miles Per Intervention,每两次人工干预之间行驶的平均里程数)成为技术迭代的核心参数指标,当下 MP I 仍处 200km 以下水平,仍需要较长的优化过程。MP I 的提升本质是安全性的提升,在正常运行环境下需要保证接管次数的下降和执行效率的 提升,同时极端环境中仍需要保持稳定。对应路径来看,当下仍采用 Learning by Watching的方式,即模仿人类行为完成驾驶的高阶动作。Learning by Watching 存在几个缺陷:(1)以行为为导向的学习模式,无法深入理解人类驾驶员思考和习惯, 单纯的行为模仿可能无法形成逻辑和数据的闭环。(2)目前传感器数据无法达到人类 对驾驶的判断,包括听觉、平衡性感知等。(3)Corner Case 存在无限性,长尾数据无法充分识别并建立对应的场景机制,车辆的思考能力是面对长尾数据的主要解决方式。(4)人类对智能驾驶的需求是要超越人类的驾驶能力,而非简单模仿,同时要 求智能驾驶在更复杂的场景中实现更好的效果。
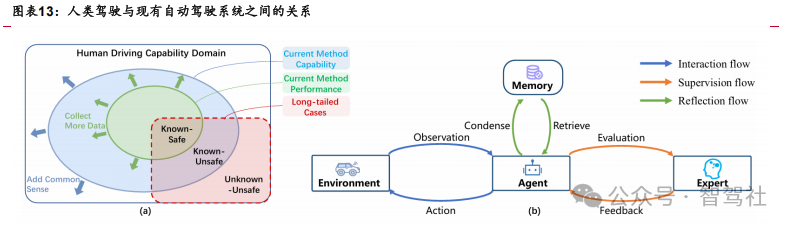
Learning by Practicing 或成为后续主要迭代方向,到 L4 车辆或具备“智能体”的能力。Learning by Practicing 中,生成式的视觉模型是构建世界模型主要方法,通过模型预测生成视觉方式完成车辆世界认知构建,并具备预测生成能力。车辆具备 对未来预测的能力和判断能力,在准确性提升后保持高阶功能的安全性。

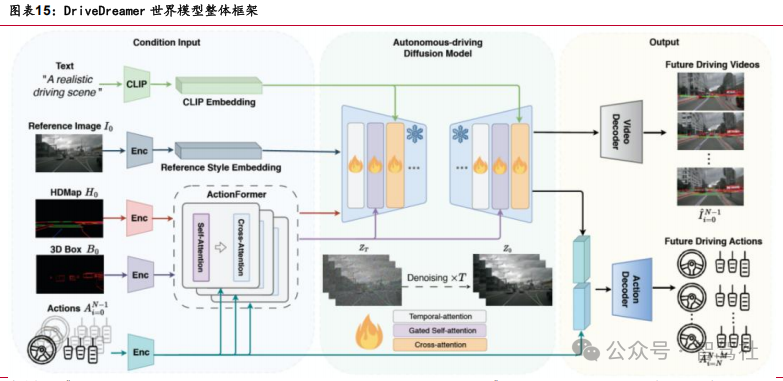
世界认知模型:Learning by Practicing 主要训练方向,或成为实现 L4 的主要解决方案。原始图像空间中学习世界模型并不适合自动驾驶,(1)交通灯、标识牌很容易在预测图像中被遗漏;(2)数据转化需要较长的时间和过程。世界模型将世界建模与模仿学习相结合,作为辅助任务实现数据集中样本复杂度的降低。同时,世界认知模型通过分解的世界模型和奖励函数来丰富静态数据集的标签,通过动态规划优化标签。世界认知模型可以认为是端到端大模型的“教材”,用标准化的内容帮助大模型完成世界认知和数据信息的构建,成为智能驾驶端到端大模型迭代的核心一环。同时在未来 Learning by Practicing 的训练模式中,通过世界模型提高模型的认知能力或成为实现 L4 智能驾驶的关键。
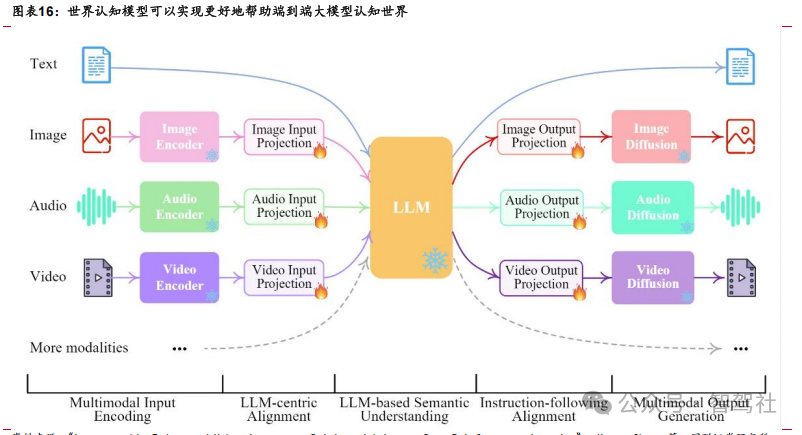
2.1 模型蒸馏:高质量教师模型、低数据损失成为重要因素
车云模型:Rule-based、Transformer 向端到端阶段升级过程中,从强调车端模型完 整性逐步转化为车云协同。Rule-based、Transformer 阶段,车端模型完整性要求较 高,即需要完成车规级的运算和安全性检测。大模型阶段,车云协同模型的完整性成 为关键,云端训练大模型后蒸馏小模型,在车端运行小模型。车端和云端对比来看, 车端受制于车端算力、续航里程等方面的影响,需要对云端模型进行压缩。
2.1 模型蒸馏:高质量教师模型、低数据损失成为重要因素
车云模型:Rule-based、Transformer 向端到端阶段升级过程中,从强调车端模型完 整性逐步转化为车云协同。Rule-based、Transformer 阶段,车端模型完整性要求较高,即需要完成车规级的运算和安全性检测。大模型阶段,车云协同模型的完整性成为关键,云端训练大模型后蒸馏小模型,在车端运行小模型。车端和云端对比来看, 车端受制于车端算力、续航里程等方面的影响,需要对云端模型进行压缩。
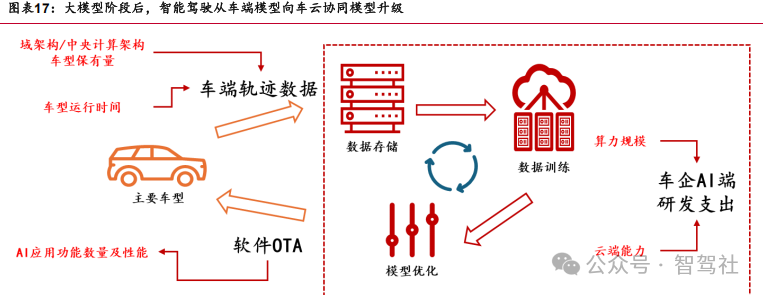
云端模型:多模态教师模型蒸馏后作为车端模型完成功能升级。在云端大模型向车端大模型输出的过程中,需要通过蒸馏完成车端模型的训练,即将云端模型作为“教 师模型”,训练成果成为车端模型的训练依据。在完整的数据链路中,需要车端完成轨迹及车辆信息的上传,完成云端存储及云端训练后优化云端大模型,而后蒸馏成车端小模型,完成对车辆功能的软件 OTA。DeepSeek 具备模块化蒸馏能力。同时模块化的能力解决了端到端的黑盒问题,增强智能驾驶算法的可解释性、可跟踪性。在智能驾驶升级过程中,云端模型的成果和蒸馏的损失或成为影响质量的关键因素。
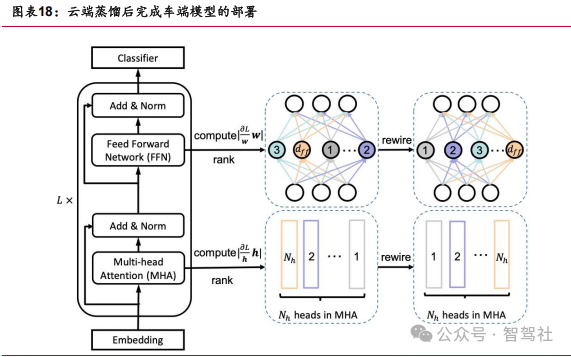
云端模型能力:优化云端 “教师模型”,数据规模、算力规模仍是车企核心比拼方向。多模态蒸馏成为云端优化后车端升级的关键。云端模型训练过程中,仍需要对世 界模型、VLA 模型等核心模型进行训练并优化训练成果。云端模型优化过程中,训练 算力规模、数据规模仍是云端“教师模型”能力提升的核心参数指标。
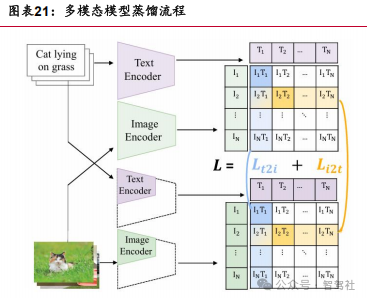
无损蒸馏能力:多模态模型在蒸馏过程中匹配度增强实现蒸馏损失降低。 以语言和图像的多模态信息蒸馏为例,蒸馏过程中通过增强信息匹配度、数据链路完整性和损失信息多次学习的方式降低蒸馏过程中“教师模型”的成果损失,优化车端表现。
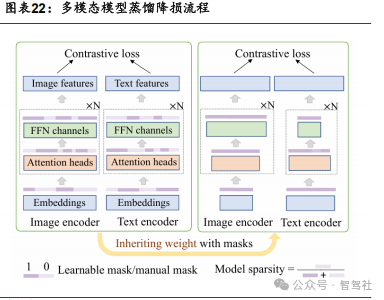
2.2 成本优化:DeepSeek 成本优势拓宽智驾工程化应用边界
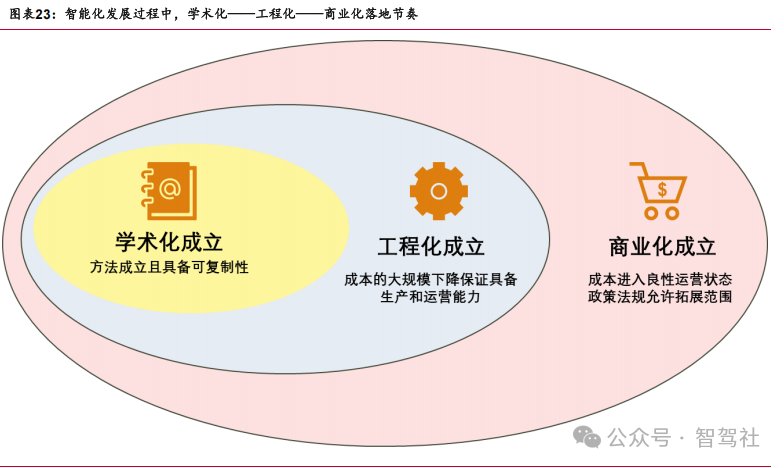
智能化推进过程中,主要经历三个阶段:学术化——工程化——商业化。学术化要求可以实现功能,同时具备可复制性。工程化要求功能可实现、可复制的同时,成本端持续可控,实现大规模量产。商业化在可以实现大规模量产要求的同时,需要有充分 的使用环境和政策支持。
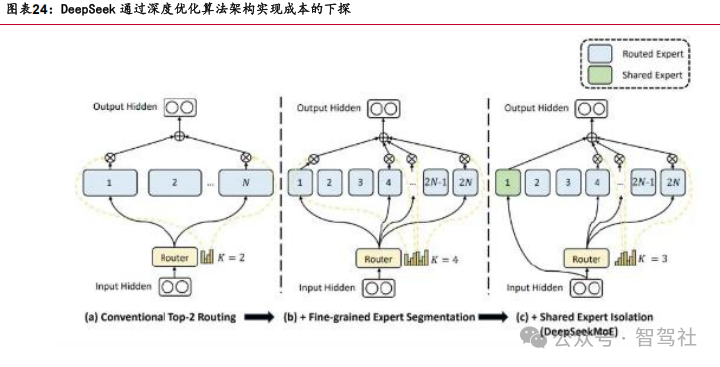
DeepSeek 算法优势明显,通过多维度方式降低 GPU 通讯成本,实现训练成本下降。
(1)DeepSeek 使用不需要辅助损失函数的专家加载均衡技术,保证每个 token 在专家网络的充分填充,降低了对数据规模的依赖。(2)DeepSeek 可以通过极致的流水线调度,把 GPU 中用于模型训练中数学运算的算力,和通信相关的算力在流水线执 行过程中进行“并行隐藏”,实现了在训练过程所有的时间中 GPU 几乎不间断地进行 运算。(3)DeepSeek 充分利用专家网络被稀疏激活的设计,限制了每个 token 被发 送往 GPU 集群节点的数量,降低GPU间通讯成本。(4)DeepSeek 还实现并应用了 FP8 混合精度训练的架构,在架构中的不同计算环节,灵活地、交替地使用 FP8、BF16、 FP32 不同精度的“数字表示”,并在参数通信的部分过程也应用了FP8 传输。
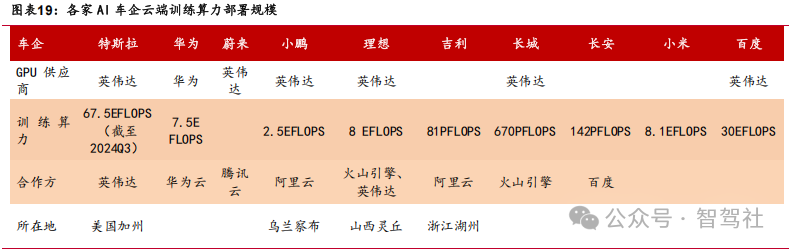
架构:DeepSeek 架构或成为全栈自研智能驾驶大模型架构的车企/供应商的主要选项,同时开源模型有望在云端训练上实现成本优势的复刻。 车企有望通过介入DeepSeek 并推出DeepSeek-R1 Beta 版本,持续优化训练算力的成本优势,实现智能驾驶成本的大幅度下降和高阶功能的工程化落地 。华为小艺、吉利持续加速与 DeepSeek 的合作,助力自身模型的持续迭代。

模型迭代处于加速阶段,DeepSeek 有望成为迭代加速“引擎”。以特斯拉为例,大版本迭代速度逐步缩短,FSD12 后实现季度大版本迭代。DeepSeek 全面加速智能驾驶迭代。DeepSeek 作为开源基础模型,引入后有望加速智能驾驶的训练速度,降低智能驾驶的训练成本,未来有望成为智能驾驶训练的主要工具。我们认为 DeepSeek 的持续迭代和效率提升是成为智能驾驶行业持续加速的关键因素。
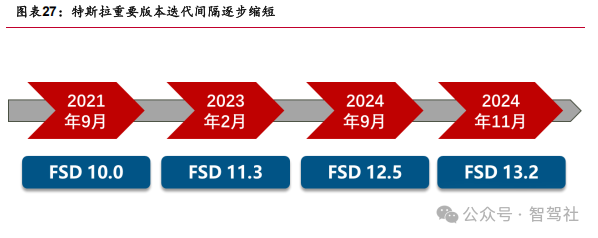
DeepSeek 或无法改变行业格局。一方面智能驾驶安全边界较高,仍需要较长训练时 长保证功能安全;另一方面针对不同车型算力和架构,蒸馏后仍需要完成定向开发。 未来功能实现层面来看,尚未实现智能驾驶功能完整性部署前,DeepSeek 的使用或 加速缩小各家车企之间的时间差距。实现功能突破后,智能驾驶领先企业有望保持用户粘性和高阶功能性能的领先。
注:文章来源智驾社
·END·
关于广州国际汽车展览会


微信扫码预登记,免排队快速入场












